作者:FserSuN
来源:https://blog.csdn.net/Revivedsun/article/details/71022871
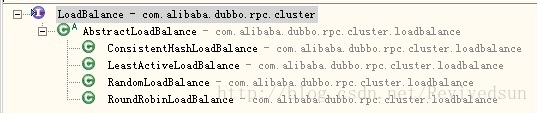
LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,以分摊压力。Dubbo中LoadBalance结构如下图。
1
2
3
4
| com.alibaba.dubbo.rpc.cluster.LoadBalance
接口提供了
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
通过该方法,进行结点选择。
|
1
2
3
4
| com.alibaba.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance
实现了一些公共方法,并定义抽象方法
protected abstract <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation);
该方法由具体的负载均衡实现类去实现。
|
一致性哈希负载均衡配置
具体的负载均衡实现类包括4种。分别是随机、轮训、最少活跃、一致性Hash
一致性哈希负载均衡配置
配置如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <dubbo:service interface="..." loadbalance="consistenthash" />
或:
<dubbo:reference interface="..." loadbalance="consistenthash" />
或:
<dubbo:service interface="...">
<dubbo:method name="..." loadbalance="consistenthash"/>
</dubbo:service>
或:
<dubbo:reference interface="...">
<dubbo:method name="..." loadbalance="consistenthash"/>
</dubbo:reference
|
一致性Hash负载均衡涉及到两个主要的配置参数为hash.arguments 与hash.nodes。
hash.arguments : 当进行调用时候根据调用方法的哪几个参数生成key,并根据key来通过一致性hash算法来选择调用结点。例如调用方法invoke(String s1,String s2); 若hash.arguments为1(默认值),则仅取invoke的参数1(s1)来生成hashCode。
hash.nodes: 为结点的副本数。
1
2
3
4
5
| 缺省只对第一个参数Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" />
缺省用160份虚拟节点,如果要修改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
|
Dubbo中一致性Hash的实现分析
dubbo的一致性哈希通过ConsistentHashLoadBalance类来实现。
ConsistentHashLoadBalance内部定义ConsistentHashSelector类,最终通过该类进行结点选择。ConsistentHashLoadBalance实现的doSelect方法来利用所创建的ConsistentHashSelector对象选择结点。
doSelect的实现如下。当调用该方法时,如果选择器不存在则去创建。随后通过ConsistentHashSelector的select方法选择结点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @SuppressWarnings("unchecked")
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
int identityHashCode = System.identityHashCode(invokers);
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
if (selector == null || selector.getIdentityHashCode() != identityHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, invocation.getMethodName(), identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
|
ConsistentHashSelector在构造函数内部会创建replicaNumber个虚拟结点,并将这些虚拟结点存储于TreeMap。随后根据调用方法的参数来生成key,并在TreeMap中选择一个结点进行调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
| private static final class ConsistentHashSelector<T> {
private final TreeMap<Long, Invoker<T>> virtualInvokers;
private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
public ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = System.identityHashCode(invokers);
URL url = invokers.get(0).getUrl();
this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);
String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i ++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
for (Invoker<T> invoker : invokers) {
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(invoker.getUrl().toFullString() + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
public int getIdentityHashCode() {
return identityHashCode;
}
public Invoker<T> select(Invocation invocation) {
String key = toKey(invocation.getArguments());
byte[] digest = md5(key);
Invoker<T> invoker = sekectForKey(hash(digest, 0));
return invoker;
}
private String toKey(Object[] args) {
StringBuilder buf = new StringBuilder();
for (int i : argumentIndex) {
if (i >= 0 && i < args.length) {
buf.append(args[i]);
}
}
return buf.toString();
}
private Invoker<T> sekectForKey(long hash) {
Invoker<T> invoker;
Long key = hash;
if (!virtualInvokers.containsKey(key)) {
SortedMap<Long, Invoker<T>> tailMap = virtualInvokers.tailMap(key);
if (tailMap.isEmpty()) {
key = virtualInvokers.firstKey();
} else {
key = tailMap.firstKey();
}
}
invoker = virtualInvokers.get(key);
return invoker;
}
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[0 + number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes = null;
try {
bytes = value.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.update(bytes);
return md5.digest();
}
}
|
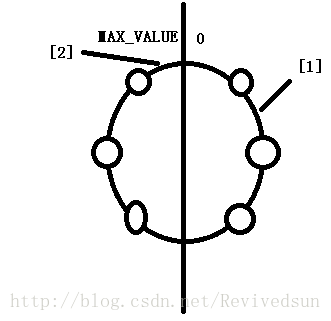
上述代码中 hash(byte[] digest, int number)方法用来生成hashCode。该函数将生成的结果转换为long类,这是因为生成的结果是一个32位数,若用int保存可能会产生负数。而一致性hash生成的逻辑环其hashCode的范围是在 0 - MAX_VALUE之间。因此为正整数,所以这里要强制转换为long类型,避免出现负数。
进行结点选择的方法为select,最后通过sekectForKey方法来选择结点。
1
2
3
4
5
6
7
8
9
10
11
|
public Invoker<T> select(Invocation invocation) {
String key = toKey(invocation.getArguments());
byte[] digest = md5(key);
Invoker<T> invoker = sekectForKey(hash(digest, 0));
return invoker;
}
|
sekectForKey方法的实现如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| private Invoker<T> sekectForKey(long hash) {
Invoker<T> invoker;
Long key = hash;
if (!virtualInvokers.containsKey(key)) {
SortedMap<Long, Invoker<T>> tailMap = virtualInvokers.tailMap(key);
if (tailMap.isEmpty()) {
key = virtualInvokers.firstKey();
} else {
key = tailMap.firstKey();
}
}
invoker = virtualInvokers.get(key);
return invoker;
}
|
在进行选择时候若HashCode直接与某个虚拟结点的key一样,则直接返回该结点,例如hashCode落在某个结点上(圆圈所表示)。若不在,找到一个最小上届的key所对应的结点。例如进行选择时的key落在图中1所标注的位置。由于利用TreeMap存储,key所落在的位置可能无法找到最小上界,例如图中2所标注的位置。那么需要返回TreeMap中的最小值(构成逻辑环状结构,找不到,则返回最开头的结点)。